- Bedrijfsvoering
- 1 februari 2022
- Leestijd: 9 minuten
Sorry, we gaven je even geen plezier
Sorry is het minste dat we kunnen zeggen na vandaag. Als ondernemer moet je elke dag kunnen vertrouwen op Moneybird. Maar op sommige dagen heb je ons nét iets harder nodig, bijvoorbeeld als je op de laatste dag voor de btw-aangifte deadline je boekhouding nog wilt bijwerken. 31 januari is zo’n dag en wij waren niet in topvorm om jullie te te helpen.
Het snel en online houden van Moneybird is een dagelijkse taak van ons team. We houden dit continu in de gaten door uitgebreide controles. En we moeten regelmatig optimalisaties doorvoeren om te zorgen dat Moneybird snel blijft. We zoeken daarbij een balans tussen voldoende inkopen om pieken op te vangen en niet teveel inkopen zodat de kosten niet te hoog worden.
Op 31 januari 2022 zijn we overvallen door een extreme piek in gebruikers op het Moneybirdplatform. Hierdoor waren de buffers niet voldoende en werd Moneybird traag. Uiteindelijk waren we genoodzaakt om Moneybird offline te halen om grotere problemen te voorkomen. Door maatregelen te nemen, konden we na een half uur Moneybird weer online zetten.
De samenvatting hierboven is een versimpelde uitleg over wat er is gebeurd. In het kader van volledige transparantie, kun je hieronder de volledige technische post mortem lezen en wat we gaan doen om te verbeteren. We hopen hiermee het vertrouwen te geven dat we serieus om gaan met deze problemen. We realiseren ons dat dit soort storingen tijdens cruciale dagen onacceptabel is. We doen er alles aan om dit in de toekomst te voorkomen.
Post mortem #
Moneybird draait op een infrastructuur van Amazon Web Services. We gebruiken daarvoor een Kubernetes-cluster, RDS PostgreSQL-database, OpenSearch-cluster en Redis-cluster.
31 januari, 10:00 uur #
De eerstelijnsengineer krijgt een waarschuwing dat onze RDS-database nog maar 80% burst credits over heeft. Bovenop de standaard Input/Output Operations per second (iops) van de database, mogen we korte tijd meer iops gebruiken. Daarvoor heeft een database een burst creditsaldo dat je langzaam verbruikt als je meer iops verbruikt. En je krijgt continu nieuwe credits. Bij de eerste melding zijn we het platform intensiever in de gaten gaan houden, maar er was nog geen reden tot zorgen omdat in veel gevallen de piek tijdelijk is.
10:55 uur #
De waarschuwing escaleert naar een storingsmelding omdat we zakken onder 30% burst credits. Dit is in hele korte tijd snel gedaald.
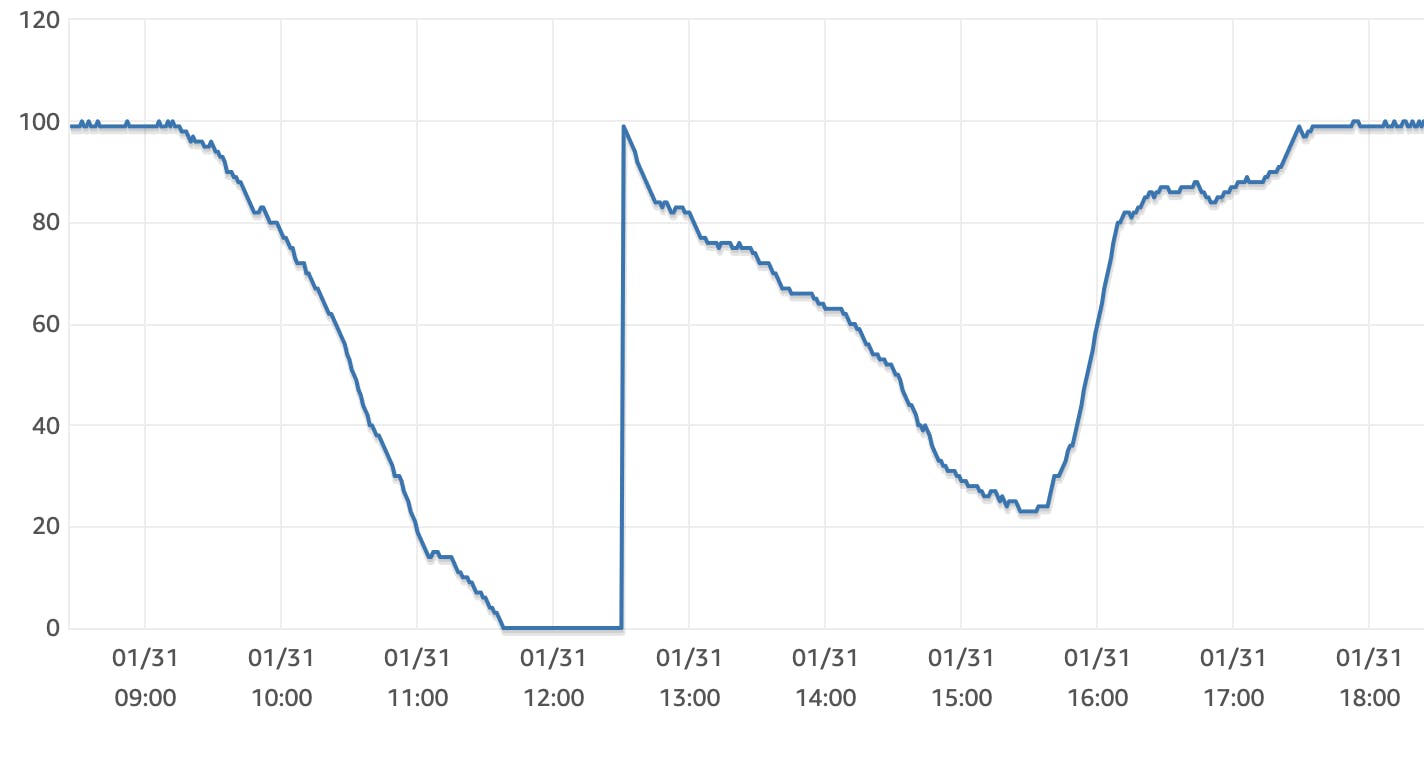
In eerdere situaties was zo’n snelle daling toe te schrijven aan een fout in onze software. We doen dan bijvoorbeeld een query die inefficiënt is. De oplossing was vaak eenvoudig: door de query uit te schakelen of te optimaliseren, konden we snel burst credits terugkrijgen en het platform weer snel maken.
In de tussentijd waren vier DevOps engineers de situatie aan het onderzoeken. Maar we konden geen aanwijzing vinden van één fout in de software. We zagen wel een grote piek in het aantal requests op ons platform. Waar we normaal rond de 9.000 requests per minuut doen, zat dat deze ochtend rond de 15.000 requests per minuut. Een stijging van meer dan 60% dus.
11:05 uur #
De engineers besluiten tijd te kopen door alle achtergrondprocess van Moneybird stop te zetten. In deze background jobs voeren we niet-urgente handelingen uit zoals het versturen van facturen en het automatisch koppelen van banktransacties. Een vertraging hierop heeft geen directe invloed op gebruikers van de applicatie en kan de database wat ademruimte geven. De snelle daling van de burst credits lijkt hierdoor te stabiliseren.
In de tussentijd kijkt het team naar verbeteringen aan de software om minder belasting op de database te krijgen, maar hier lijkt geen snelle winst te halen.
Een ander pad dat we onderzoeken is het upgraden van de databasestorage om meer iops en burst credits te krijgen. Het onderzoek hiernaar kost enige tijd omdat we met een upgrade geen aanvullende storingen willen veroorzaken en we de upgrade in één keer goed moeten doen omdat we daarna 6 uur niets kunnen wijzigen.
11:38 uur #
Ondanks het stoppen van de background jobs, zijn de burst credits nu op. Doordat we dit aan zagen komen konden we onze klanten op tijd informeren via onze statuspagina en zat het supportteam klaar om vragen te beantwoorden.
Vanwege de oplopende queue voor background jobs en de druk die dit geeft op het Redis cluster, besluiten we om de background jobs weer te gaan afhandelen.
Doordat de burst credits op zijn, valt de database terug naar de standaard snelheid. Deze snelheid is normaal gesproken meer dan voldoende, maar met het aantal klanten op het platform is alles heel traag aan het worden. Hierdoor lopen de read en write latency van query’s op en gaan query’s falen vanwege statement timeouts.
12:30 uur #
We zijn nu zeker dat het upgraden van de databasestorage de enige manier is om snel meer iops te krijgen. Bovendien weten we zeker dat de database online zal blijven tijdens de upgrade en er geen extra vertraging zal optreden. We hebben berekend hoeveel iops nodig zijn om de piek aan te kunnen en zetten de upgrade in werking.
Door de opzet van de AWS RDS burst credits krijgen we gelijk 100% credits na de upgrade. Hierdoor is de storing nagenoeg gelijk verholpen en is Moneybird weer snel. Onze berekeningen wezen uit dat de hogere baseline en hogere credit groei gaat zorgen dat we de ongebruikelijke druk op het platform aan kunnen.
13:01 uur #
Na de situatie een half uur gemonitord te hebben, melden we de storing af op onze statuspagina. De drukte blijft, maar de database lijkt het goed te houden.
14:10 uur #
Alle alarmbellen gaan weer af. We krijgen een automatische melding dat het aantal 500 fouten op het platform hoog is. De background queues lopen vol met foutmeldingen. En een opvallend hoog aantal klanten mailt met “storing” in het bericht.
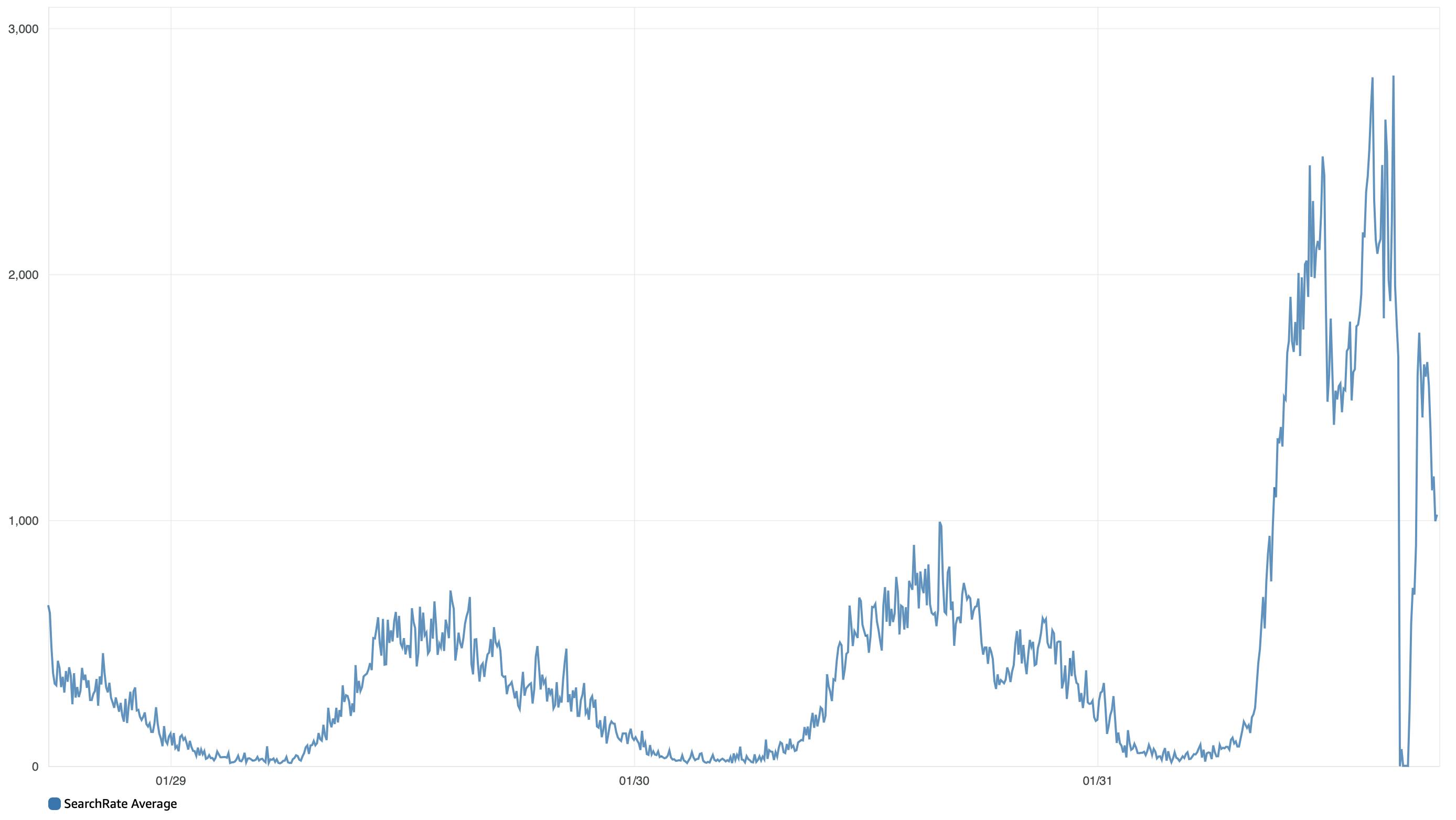
De oorzaak blijkt te zitten in het OpenSearch cluster. Alle zoekacties voor contacten en facturen lopen via dit cluster. In de grafieken van het gemiddelde aantal zoekacties per 5 minuten is de piek duidelijk te zien:
Bij nader onderzoek blijkt dat alle instances in het cluster aan de maximale CPU zitten:
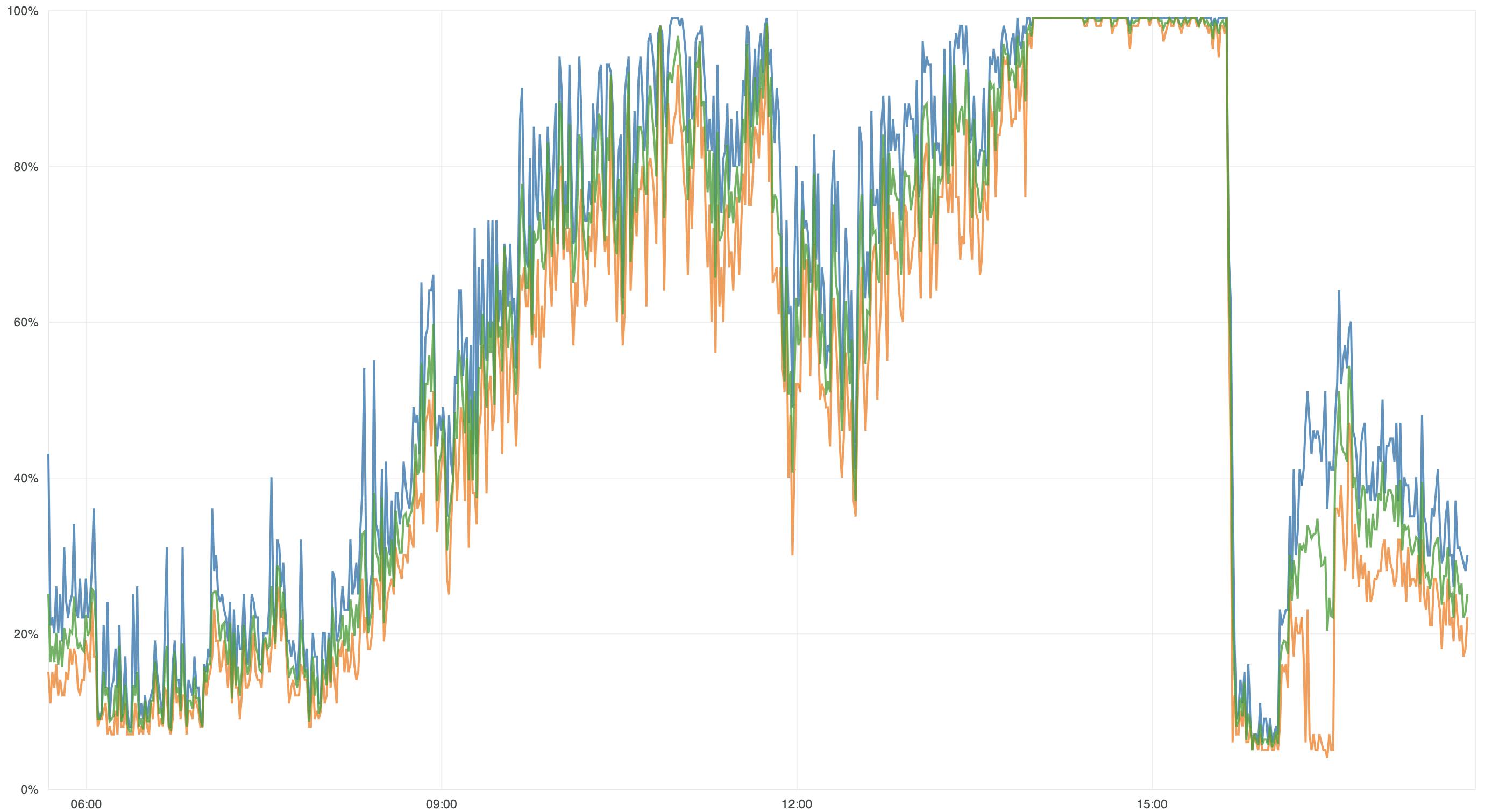
We weten dat het upgraden van de instances zonder downtime kan, maar wel impact heeft op de CPU. Door het hoge CPU verbruik kan het dus gebeuren dat het hele cluster alsnog onbereikbaar wordt.
We besluiten weer de background jobs tijdelijk te stoppen zodat hopelijk wat ademruimte ontstaat de upgrade uit te kunnen voeren. Dit blijkt een minimaal effect te hebben, echter niet voldoende om de upgrade veilig uit te kunnen voeren.
15:03 uur #
In de tussentijd hebben we gezien dat de database zijn burst credits ook snel aan het verbruiken is. Ondanks onze berekening, blijkt dat we niet voldoende storage ingekocht hebben. Helaas zitten we in de 6-uur window van AWS RDS waarin we niet verder kunnen upgraden.
Vanwege de naderende aangifte deadline, blijven klanten ook zeer actief op het platform. We bedenken verschillende oplossingen voor het spreiden van het verkeer. Helaas is geen van de oplossingen op korte termijn te bouwen.
In de tussentijd loopt de background queue zeer vol en dreigt ook het Redis cluster in de problemen te komen. We nemen daarom een radicaal besluit: we halen Moneybird volledig offline om ademruimte te krijgen.
15:34 uur #
De situatie is ondertussen verder geëscaleerd binnen het team. Naast een team van 6 engineers, sluiten nu ook het management, communicatie en support aan. Het crisisteam stelt een communicatieplan op waarin we klanten goed op te hoogte willen houden van de situatie.
Even later gaat Moneybird definitief in onderhoudsmodus. In korte tijd halen we hierdoor alle druk van het platform. Kort daarna starten we een upgrade van het OpenSearch cluster. We werken alle background jobs af zodat Redis weer leeg is. En RDS krijgt de kans om burst credits op te bouwen.
16:05 uur #
De upgrade van OpenSearch is afgerond en de database heeft weer meer dan 80% burst credits. We zetten Moneybird weer online. We besluiten hierover nog niet breed te communiceren zodat het verkeer langzaam kan opbouwen.
16:42 uur #
We melden de storing af op onze statuspagina. Hoewel het verkeer weer bijna op het niveau van voor de downtime zit, lijken de database en de zoekfunctie het nu goed bij te kunnen houden. We blijven de situatie continu monitoren.
Wat gaan we verbeteren? #
Het verkeer op Moneybird is zeer infrequent. In weekenden is er nauwelijks verkeer en op specifieke dagen voor een deadline is er veel verkeer. Dit patroon kennen we al jaren. De webservers en background queues schalen hiervoor automatisch mee. Voor de onderliggende infrastructuur zoals PostgreSQL, OpenSearch en Redis is dat moeilijk(er) te realiseren.
In voorgaande jaren hebben we nog nooit een 60% stijging in verkeer gehad op één dag. Onze buffers zijn goed in staat om de gebruikelijke pieken op te vangen, maar deze ongebruikelijke piek hebben we niet aan zien komen. We denken dat deze te verklaren valt door een combinatie van factoren:
- 31 januari valt op een maandag. Waar we normaal een hele week meer drukte zien vanwege de aangiftes, hebben nu veel ondernemers het over het weekend getild.
- Ondernemers werken soms in het weekend hun boekhouding bij. Zondag 30 januari was een uitzonderlijk warme en zonnige dag. Dus minder ondernemers hebben aangifte in het weekend gedaan.
- Nieuwe functionaliteit zoals de elektronische btw-aangifte zorgen dat het aantal ondernemers dat zelf hun aangifte doet continu stijgt. Hierdoor is de piek in onze software merkbaarder dan wanneer de aangifte op een andere manier gedaan wordt.
- De groei van Moneybird is in de afgelopen jaren groot geweest.
- Door de lancering van Moneybird Payments zijn we volop in de aandacht geweest, hierdoor starten meer ondernemers met Moneybird.
We zijn tevreden over het signaleren van de storingen. In de meeste gevallen zagen we de problemen tijdig aankomen. Voor de storing in het OpenSearch cluster gaan we extra monitoring toevoegen zodat we deze ook tijdig kunnen signaleren.
We waren proactief met het communiceren naar klanten, waardoor klanten wisten waar ze aan toe waren. De meldingen stonden snel op onze statuspagina. Klanten kregen snel reactie via e-mail en op social media. Via een melding in de applicatie konden we klanten op de hoogte brengen van de vertraging. Niemand wil horen dat je een storing hebt, maar de onzekerheid als iets niet werkt zoals je verwacht is nog vervelender.
We gaan in de toekomst onze buffers nog groter maken om dit soort onverwachte pieken op te vangen. Hiervoor gaan we niet alleen leunen op onze historische data over pieken, maar nog meer kijken naar potentiële combinaties van factoren waardoor we een grote piek kunnen krijgen.
We gaan onze software efficiënter schrijven op bepaalde punten zodat we minder zware query’s uitvoeren. Ook hebben we nieuwe ideeën gekregen over caching van zware query’s.
Door deze maatregelen te nemen hopen we de pieken beter op te kunnen vangen en ervoor te zorgen dat we nooit meer offline hoeven te gaan op dagen dat ondernemers écht op ons moeten kunnen vertrouwen.